Time 🟡¶
Resulting code: step095-timestamp-queries
Resulting code: step095-timestamp-queries-vanilla
We start by measuring compute time, which is often the most valuable resource.
Warning
As of September 6, 2023, wgpu-native does not support timestamp queries yet. I suggest you follow this chapter with Dawn only for now.
Asynchronicity¶
Importantly, measuring GPU time is quite different from measuring CPU time, because as you may recall we only interact with the GPU through remote calls issued in our CPU code (C++).
In an imperative CPU code, measuring time looks like this:
# Pseudocode of a simple CPU benchmarking
start_time = get_current_time()
do_on_cpu(something)
end_time = get_current_time()
ellapsed = end_time - start_time
But when doing this on the GPU, we only submit operations that run on a different timeline:
# Pseudocode of a **wrong** GPU benchmarking
start_time = get_current_time()
submit_to_do_on_gpu(something)
end_time = get_current_time()
ellapsed = end_time - start_time # wrong!
The “something” may not even have started at this point. What we measure is the time it takes to submit instructions, not to actually execute them!
Timestamp Queries¶
We must instruct the GPU to run some equivalent of get_current_time() on its own timeline. The result of this operation is stored in a dedicated object called a timestamp query.
# Pseudocode of a correct GPU benchmarking
start_timestamp_query = create_timestamp_query()
end_timestamp_query = create_timestamp_query()
submit_to_do_on_gpu(write_current_time, start_timestamp_query)
submit_to_do_on_gpu(something)
submit_to_do_on_gpu(write_current_time, end_timestamp_query)
We must then fetch the timestamp values back to the CPU, through a mapped buffer like we see in Playing with buffers.
🫡 Okay, got it, so what about actual C++ code?
Whether they measure timestamps or other things, GPU queries are stored in a QuerySet. We typically store both the start and end time in the same set:
// Create timestamp queries
QuerySetDescriptor querySetDesc;
querySetDesc.type = QueryType::Timestamp;
querySetDesc.count = 2; // start and end
QuerySet timestampQueries = device.createQuerySet(querySetDesc);
// Create timestamp queries
WGPUQuerySetDescriptor querySetDesc;
querySetDesc.nextInChain = nullptr;
querySetDesc.type = WGPUQueryType_Timestamp;
querySetDesc.count = 2; // start and end
WGPUQuerySet timestampQueries = wgpuDeviceCreateQuerySet(device, &querySetDesc);
Note
I base this example on step095, from chapter Simple GUI
Note
I created a initBenchmark() method (called in onInit) to initialize benchmark-related objects like the query set. I also created a terminateBenchmark() to release these resources.
However, if you try to add the code block above to your application, you will face an error:
Device error: (Dawn) Timestamp queries are disallowed because they may expose precise timing information. (wgpu-native) Features(TIMESTAMP_QUERY) are required but not enabled on the device.
Enabling Timestamp Feature¶
Dawn toggles¶
Let us start with Dawn: for privacy reasons, Dawn disables timing information. This is relevant when running on the Web, but not in our native application context. Fortunately, this safeguard can easily be disabled.
Dawn has a list of so-called “toggles” that can be turned on or off at the scale of the whole WebGPU instance: the list is available in Toggles.cpp.
To enable toggles, we use the Dawn-specific DawnTogglesDescriptor extension, which can be chained to the instance descriptor:
// At the very beginning of onInit()
InstanceDescriptor instanceDesc;
#ifdef WEBGPU_BACKEND_DAWN
// Dawn-specific extension to enable/disable toggles
DawnTogglesDescriptor dawnToggles;
// [...]
instanceDesc.nextInChain = &dawnToggles.chain;
#endif
m_instance = createInstance(instanceDesc);
// At the very beginning of onInit()
WGPUInstanceDescriptor instanceDesc;
#ifdef WEBGPU_BACKEND_DAWN
// Dawn-specific extension to enable/disable toggles
WGPUDawnTogglesDescriptor dawnToggles;
// [...]
instanceDesc.nextInChain = &dawnToggles.chain;
#endif
m_instance = wgpuCreateInstance(&instanceDesc);
We then specify that we want to enable the allow_unsafe_apis feature:
#ifdef WEBGPU_BACKEND_DAWN
DawnTogglesDescriptor dawnToggles;
dawnToggles.chain.next = nullptr;
dawnToggles.chain.sType = SType::DawnTogglesDescriptor;
std::vector<const char*> enabledToggles = {
"allow_unsafe_apis",
};
dawnToggles.enabledToggles = enabledToggles.data();
dawnToggles.enabledTogglesCount = enabledToggles.size();
dawnToggles.disabledTogglesCount = 0;
instanceDesc.nextInChain = &dawnToggles.chain;
#endif
#ifdef WEBGPU_BACKEND_DAWN
WGPUDawnTogglesDescriptor dawnToggles;
dawnToggles.chain.next = nullptr;
dawnToggles.chain.sType = WGPUSType_DawnTogglesDescriptor;
std::vector<const char*> enabledToggles = {
"allow_unsafe_apis",
};
dawnToggles.enabledToggles = enabledToggles.data();
dawnToggles.enabledTogglesCount = enabledToggles.size();
dawnToggles.disabledTogglesCount = 0;
instanceDesc.nextInChain = &dawnToggles.chain;
#endif
Note
The toggles descriptor can also be used as an extension of the adapter or device request options. In that case, device toggles supersede adapter toggles, which supersede instance toggles.
The error message we get is now slightly different:
Device error: (Dawn) Timestamp query set created without the feature being enabled.
This is in substance the same error than the one reported by wgpu-native above, we treat both in the next section.
Feature request¶
When creating our WebGPU device, we mentioned already that we can set up specific limits. But we can also request specific features from the WGPUFeatureName enum. In particular, we need to enable FeatureName::TimestampQuery.
std::vector<FeatureName> requiredFeatures = {
FeatureName::TimestampQuery,
};
deviceDesc.requiredFeatures = (const WGPUFeatureName*)requiredFeatures.data();
deviceDesc.requiredFeaturesCount = (uint32_t)requiredFeatures.size();
std::vector<WGPUFeatureName> requiredFeatures = {
WGPUFeatureName_TimestampQuery,
};
deviceDesc.requiredFeatures = requiredFeatures.data();
deviceDesc.requiredFeaturesCount = (uint32_t)requiredFeatures.size();
The error messages should now be fixed! You may also want to check that the adapter, and then the device, support this feature:
std::vector<FeatureName> requiredFeatures;
if (m_adapter.hasFeature(FeatureName::TimestampQuery)) {
requiredFeatures.push_back(FeatureName::TimestampQuery);
}
// [...] Create device
if (!m_device.hasFeature(FeatureName::TimestampQuery)) {
std::cout << "Timestamp queries are not supported!" << std::endl;
}
std::vector<WGPUFeatureName> requiredFeatures;
if (wgpuAdapterHasFeature(m_adapter, WGPUFeatureName_TimestampQuery)) {
requiredFeatures.push_back(WGPUFeatureName_TimestampQuery);
}
// [...] Create device
if (!wgpuDeviceHasFeature(m_device, WGPUFeatureName_TimestampQuery)) {
std::cout << "Timestamp queries are not supported!" << std::endl;
}
Note
Timestamp queries are specified as an explicit feature because some devices/adapters may not support them.
Writing timestamps¶
There are different ways of writing timestamp into queries. The closest one to our pseudocode above is commandEncoder.writeTimestamp(), which writes the GPU-side time into a query whenever the command is executed in the GPU timeline.
If you want more specifically to measure the time taken by a render or compute pass, you can also pass timestamp queries to the passes descriptor:
// In Application::onFrame()
std::vector<RenderPassTimestampWrite> timestampWrites(2);
timestampWrites[0].location = RenderPassTimestampLocation::Beginning;
timestampWrites[0].querySet = m_timestampQueries;
timestampWrites[0].queryIndex = 0; // first query = start time
timestampWrites[1].location = RenderPassTimestampLocation::End;
timestampWrites[1].querySet = m_timestampQueries;
timestampWrites[1].queryIndex = 1; // second query = end time
renderPassDesc.timestampWriteCount = (uint32_t)timestampWrites.size();
renderPassDesc.timestampWrites = timestampWrites.data();
RenderPassEncoder renderPass = encoder.beginRenderPass(renderPassDesc);
// In Application::onFrame()
std::vector<WGPURenderPassTimestampWrite> timestampWrites(2);
timestampWrites[0].location = WGPURenderPassTimestampLocation_Beginning;
timestampWrites[0].querySet = m_timestampQueries;
timestampWrites[0].queryIndex = 0; // first query = start time
timestampWrites[1].location = WGPURenderPassTimestampLocation_End;
timestampWrites[1].querySet = m_timestampQueries;
timestampWrites[1].queryIndex = 1; // second query = end time
renderPassDesc.timestampWriteCount = (uint32_t)timestampWrites.size();
renderPassDesc.timestampWrites = timestampWrites.data();
WGPURenderPassEncoder renderPass = wgpuCommandEncoderBeginRenderPass(encoder, &renderPassDesc);
Note
I initialize the query set only once and store it into an attribute m_timestampQueries of the Application class.
Reading timestamps¶
Resolving timestamps¶
Okay, the render pass writes to our first query when it begins, and writes to the second query when it ends. We only need to compute the difference now, right? But the timestamps still live in the GPU memory, so we first need to fetch them back to the CPU.
The first step consists in resolving the query. This gets the timestamp values from whatever internal representation the WebGPU implementation uses to store query set and write them in a GPU buffer.
// We create a method dedicated to fetching timestamps
void Application::resolveTimestamps(CommandEncoder encoder) {
// Resolve the timestamp queries (write their result to the resolve buffer)
encoder.resolveQuerySet(
m_timestampQueries,
0, 2, // get queries 0 to 0+2
m_timestampResolveBuffer,
0 // offset in resolve buffer
);
}
// We create a method dedicated to fetching timestamps
void Application::resolveTimestamps(WGPUCommandEncoder encoder) {
// Resolve the timestamp queries (write their result to the resolve buffer)
wgpuCommandEncoderResolveQuerySet(
encoder,
m_timestampQueries,
0, 2, // get queries 0 to 0+2
m_timestampResolveBuffer,
0 // offset in resolve buffer
);
}
And as you noticed we need to create a dedicated buffer m_timestampResolveBuffer with the QueryResolve usage. This buffers needs to reserve a 64-bit unsigned integer per timestamp:
// In Application.h
wgpu::Buffer m_timestampBuffer = nullptr;
// In Application.cpp
void Application::initBenchmark() {
// [...]
// Create buffer to store timestamps
BufferDescriptor bufferDesc;
bufferDesc.label = "timestamp resolve buffer";
bufferDesc.size = 2 * sizeof(uint64_t);
bufferDesc.usage = BufferUsage::QueryResolve; // important!
m_timestampResolveBuffer = m_device.createBuffer(bufferDesc);
}
// In Application.h
WGPUBuffer m_timestampBuffer = nullptr;
// In Application.cpp
void Application::initBenchmark() {
// [...]
// Create buffer to store timestamps
WGPUBufferDescriptor bufferDesc;
bufferDesc.label = "timestamp resolve buffer";
bufferDesc.size = 2 * sizeof(uint64_t);
bufferDesc.usage = WGPUBufferUsage_QueryResolve; // important!
bufferDesc.mappedAtCreation = false;
m_timestampResolveBuffer = wgpuDeviceCreateBuffer(m_device, bufferDesc);
}
Warning
One the Web, the timestamp resolution may include rounding the value, to avoid giving access to precise information that could lead to timing attacks.
We can call resolveTimestamps in our main loop, after renderPass.end() and before encoder.finish():
// in Application::onFrame()
renderPass.end();
resolveTimestamps(encoder);
// in Application::onFrame()
wgpuRenderPassEncoderEnd(renderPass);
resolveTimestamps(encoder);
At this stage, if we only process the timestamps on the GPU, this is all we need. We can for instance provide them as uniforms in a shader.
Fetching timestamps¶
But usually we need to read timestamps on the CPU (for instance to display them with ImGui).
We cannot directly map the resolve buffer, because buffers that have the MapRead usage can only be used for mapping. We thus create another buffer, namely the m_timestampMapBuffer:
// In Application.h
wgpu::Buffer m_timestampMapBuffer = nullptr;
// In Application.cpp
void Application::initBenchmark() {
// [...]
// add CopySrc usage here:
bufferDesc.usage = BufferUsage::QueryResolve | BufferUsage::CopySrc;
m_timestampResolveBuffer = m_device.createBuffer(bufferDesc);
bufferDesc.label = "timestamp map buffer";
bufferDesc.size = 2 * sizeof(uint64_t);
bufferDesc.usage = BufferUsage::MapRead | BufferUsage::CopyDst;
m_timestampMapBuffer = m_device.createBuffer(bufferDesc);
}
// In Application.h
WGPUBuffer m_timestampMapBuffer = nullptr;
// In Application.cpp
void Application::initBenchmark() {
// [...]
// add CopySrc usage here:
bufferDesc.usage = WGPUBufferUsage_QueryResolve | WGPUBufferUsage_CopySrc;
m_timestampResolveBuffer = wgpuDeviceCreateBuffer(m_device, bufferDesc);
bufferDesc.label = "timestamp map buffer";
bufferDesc.size = 2 * sizeof(uint64_t);
bufferDesc.usage = WGPUBufferUsage_MapRead | WGPUBufferUsage_CopyDst;
m_timestampMapBuffer = wgpuDeviceCreateBuffer(m_device, bufferDesc);
}
We then copy to this buffer right after resolution:
void Application::resolveTimestamps(CommandEncoder encoder) {
// [...] Resolve the timestamp queries (write their result to the resolve buffer)
// Copy to the map buffer
encoder.copyBufferToBuffer(
m_timestampResolveBuffer, 0,
m_timestampMapBuffer, 0,
2 * sizeof(uint64_t)
);
}
void Application::resolveTimestamps(WGPUCommandEncoder encoder) {
// [...] Resolve the timestamp queries (write their result to the resolve buffer)
// Copy to the map buffer
wgpuCommandEncoderCopyBufferToBuffer(
encoder,
m_timestampResolveBuffer, 0,
m_timestampMapBuffer, 0,
2 * sizeof(uint64_t)
);
}
And finally we map this buffer. But we must take care of doing this after the encoder has been submitted, because it is not allowed to copy to a buffer while it is being mapped. We thus create a new fetchTimestamps() method, called after queue.submit():
m_queue.submit(command);
fetchTimestamps();
m_swapChain.present();
wgpuQueueSubmit(m_queue, 1, &command);
fetchTimestamps();
wgpuSwapChainPresent(m_swapChain);
Also, remember that buffer mapping is asynchronous, so we must be careful when this fetchTimestamps() function is called at each frame.
Note
This part differs slightly in architecture depending on whether you are using the C++ wrapper or the vanilla API, I invite you to pick the right tab below:
Overall the mapping operation looks like what we did in the Playing with buffers chapter:
void Application::fetchTimestamps() {
m_timestampMapBuffer.mapAsync(MapMode::Read, 0, 2 * sizeof(uint64_t), [this](BufferMapAsyncStatus status) {
if (status != BufferMapAsyncStatus::Success) {
std::cerr << "Could not map buffer! status = " << status << std::endl;
}
else {
uint64_t* timestampData = (uint64_t*)m_timestampMapBuffer.getConstMappedRange(0, 2 * sizeof(uint64_t));
// [...] Use timestampData here.
m_timestampMapBuffer.unmap();
}
});
}
However to ensure that the callback outlives the scope in which it is defined here, we must maintain its handle in the Application class:
// In Application.h
std::unique_ptr<wgpu::BufferMapCallback> m_timestampMapHandle;
// In Application::fetchTimestamps()
m_timestampMapHandle = m_timestampMapBuffer.mapAsync(/* [...] */);
Lastly, we do not want to trigger a new mapping operation if there is already one going on! To check this, we may simply use the handle and return early whenever it is not null:
void Application::fetchTimestamps(WGPUCommandEncoder encoder) {
// If we are already in the middle of a mapping operation,
// no need to trigger a new one.
if (m_timestampMapHandle) return;
m_timestampMapHandle = m_timestampMapBuffer.mapAsync(/* [...] */ {
// [...] Use timestamp data if mapping is successful
// Release the callback and signal that there is no longer an
// ongoing mapping operation.
m_timestampMapHandle.reset();
});
}
TODO:
Define a static method to be used as callback
Add a boolean to check whether there is an ongoing mapping operation
Overall the mapping operation looks like what we did in the Playing with buffers chapter:
void Application::fetchTimestamps() {
wgpuBufferMapAsync(
m_timestampMapBuffer,
WGPUMapMode_Read,
0, 2 * sizeof(uint64_t),
[](WGPUBufferMapAsyncStatus status, void *that){
reinterpret_cast<Application*>(that)->onTimestampBufferMapped(status);
},
(void*)this
);
}
// Create a new callback method in the Application class:
void Application::onTimestampBufferMapped(WGPUBufferMapAsyncStatus status) {
if (status != WGPUBufferMapAsyncStatus_Success) {
std::cerr << "Could not map buffer! status = " << status << std::endl;
}
else {
uint64_t* timestampData = (uint64_t*)wgpuBufferGetConstMappedRange(m_timestampMapBuffer, 0, 2 * sizeof(uint64_t));
// [...] Use timestampData here.
wgpuBufferUnmap(m_timestampMapBuffer);
}
}
However, we do not want to trigger a new mapping operation if there is already one going on! To check this, we add a simple boolean attribute and return early whenever a mapping operation is already in flight:
// In Application.h
bool m_timestampMapOngoing = false;
// In Application::fetchTimestamps()
m_timestampMapHandle = m_timestampMapBuffer.mapAsync(/* [...] */);
void Application::fetchTimestamps(WGPUCommandEncoder encoder) {
// If we are already in the middle of a mapping operation,
// no need to trigger a new one.
if (m_timestampMapOngoing) return;
m_timestampMapOngoing = true;
wgpuBufferMapAsync(m_timestampMapBuffer, /* [...] */);
}
void Application::onTimestampBufferMapped(WGPUBufferMapAsyncStatus status) {
m_timestampMapOngoing = false;
// [...]
}
Thanks to this, we can now safely call fetchTimestamps() at each frame, right after submitting the command buffer.
Using timestamp values¶
Display¶
We can finally manipulate timestamp values on the CPU! At first we can display them in the terminal: in the map callback, when mapping was successful:
// Use timestampData
uint64_t begin = timestampData[0];
uint64_t end = timestampData[1];
uint64_t nanoseconds = (end - begin);
float milliseconds = (float)nanoseconds * 1e-6;
std::cout << "Render pass took " << milliseconds << "ms" << std::endl;
You get in the end a little less than 1 log line per frame:
Render pass took 0.484128ms
Render pass took 0.538624ms
Render pass took 0.49056ms
Render pass took 0.490912ms
Render pass took 0.504864ms
Render pass took 0.491872ms
Render pass took 0.487808ms
Render pass took 0.587872ms
Render pass took 0.493504ms
Render pass took 0.498112ms
Render pass took 0.547136ms
Render pass took 0.452928ms
Statistics¶
Usually, I am not interested in one line per frame, but rather in showing in the UI the mean and standard deviation of my measure. I use for this my TinyTimer.h:
// In Application.h
#include "TinyTimer.h"
class Application {
// [...]
TinyTimer::PerformanceCounter m_perf;
};
// In fetch timestamp callback
m_perf.add_sample(milliseconds * 1e-3);
// In Application::updateGui()
ImGui::Text("Application average [...]", /* [...] */);
ImGui::Text("Render pass duration on GPU: %s", m_perf.summary().c_str());
ImGui::End();
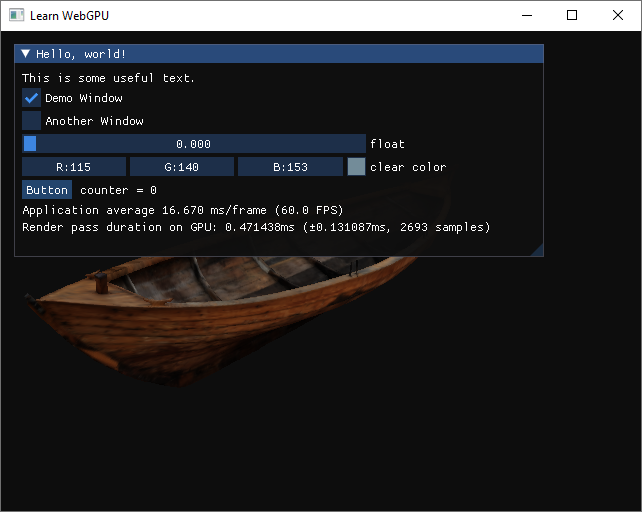
Our GPU timer displayed in the application.¶
Note
In this example, we can see that the render pass takes much less time than a frame. This is because the limiting factor here is the VSync that caps the number of frames per second to 60 (the maximum refresh rate of my display).
Important
When reporting and comparing benchmark values, and statistics in general, it is important to look at the standard deviation, but also at the number of samples on which this standard value is estimated.
Conclusion¶
You are now able to use precise GPU-side timers, which is essential to evaluate the performances of your application and identify the bottlenecks. Remember that:
GPU timers don’t live on the same timeline as CPU timers.
You need to create timestamp queries, then write to them, resolve them, and finally fetch them back asynchronously.
You must pay attention not to fetch before the resolve/copy operations are not only encoded by submitted to the GPU.
I would suggest to create a little class responsible solely for managing the timers in your application, so that the boilerplate is isolated to your application’s logic.
Note
If you want to measure performances for events that do not happen at each frame, you should keep for each such counter a boolean telling whether the counter has been updated, so that you add_sample upon fetch callback only when the timestamps were actually updated.
Resulting code: step095-timestamp-queries
Resulting code: step095-timestamp-queries-vanilla