The Command Queue 🟢¶
Resulting code: step015
Let us see one last concept before moving on to opening a window to draw on: we learn in this chapter a key concept of WebGPU (and of most modern graphics APIs as well): the command queue.
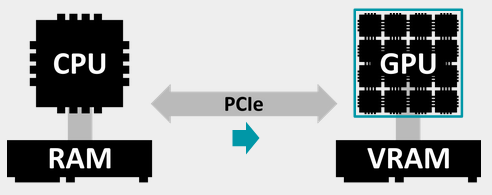
The CPU instructs the GPU what to do by sending commands through a command queue.¶
Different timelines¶
One important thing to keep in mind when doing graphics programming: we have two processors running simultaneously. One of them is the CPU, also known as host, and the other one is the GPU, or device. There are two rules:
The code we write runs on the CPU, and some of it triggers operations on the GPU. The only exception are shaders, which actually run on GPU.
Processors are “far away”, meaning that communicating between them takes time.
They are not too far, but for high performance applications like real time graphics, this matters. In advanced pipelines, rendering a frame may involve thousands or tens of thousands of commands running on the GPU.
As a consequence, we cannot afford to send the commands one by one from the CPU and wait for a response after each one. Instead, commands intended for the GPU are batched and fired through a command queue. The GPU consumes this queue whenever it is ready, and this way processors minimize the time spent idling for their sibling to respond.
The CPU-side of your program, i.e., the C++ code that you write, lives in the Content timeline. The other side of the command queue is in the Queue timeline, running on the GPU.
Note
There is also a Device timeline defined in WebGPU’s documentation. It corresponds to the GPU operations for which our code actually waits for an immediate answer (called “synchronous” calls), but unlike the JavaScript API, it is roughly the same as the content timeline in our C++ case.
Queue operations¶
Our WebGPU device has a single queue, which is used to send both commands and data. We can get it with wgpuDeviceGetQueue.
WGPUQueue queue = wgpuDeviceGetQueue(device);
We must also release the queue once we no longer use it, at the end of the program:
// At the end
wgpuQueueRelease(queue);
Note
Other graphics API allow one to build multiple queues per device, and future version of WebGPU might as well. But for now, one queue is already more than enough for us to play with!
Looking at webgpu.h, we find 3 different ways to submit work to this queue:
wgpuQueueSubmitwgpuQueueWriteBufferwgpuQueueWriteTexture
The first one only sends commands (potentially complicated ones though), and the two other ones send data from the CPU memory (RAM) to the GPU one (VRAM). This is where the delay of the communication might become particularly critical.
We also find a wgpuQueueOnSubmittedWorkDone procedure that we can use to set up a function to be called back once the work is done. Let us do it to make sure things happen as expected:
auto onQueueWorkDone = [](WGPUQueueWorkDoneStatus status, void* /* pUserData */) {
std::cout << "Queued work finished with status: " << status << std::endl;
};
wgpuQueueOnSubmittedWorkDone(queue, onQueueWorkDone, nullptr /* pUserData */);
Note
The function onQueueWorkDone is defined here as a lambda expression but it could also be a regular function declared before main(), provided it has the same signature:
void onQueueWorkDone(WGPUQueueWorkDoneStatus status, void* /*pUserData*/) {
std::cout << "Queued work finished with status: " << status << std::endl;
}
Important
Only non-capturing lambdas (i.e., with [] empty) are allowed to be passed as a callback to wgpuQueueOnSubmittedWorkDone and other asynchronous operations. Instead of capturing some context, we must use the pUserData pointer (see subsequent chapters).
Submitting commands¶
We submit commands using the following procedure:
wgpuQueueSubmit(queue, /* number of commands */, /* pointer to the command array */);
We see a typical idiom here: WebGPU is a C API so whenever it needs to receive an array of things, we first provide the array size then a pointer to the first element.
If we have a single element, it is simply:
// With a single command:
WGPUCommandBuffer command = /* [...] */;
wgpuQueueSubmit(queue, 1, &command);
wgpuCommandBufferRelease(command); // release command buffer once submitted
If we know at compile time (“statically”) the number of commands, we may use a C array (although a std::array is safer):
// With a statically know number of commands:
WGPUCommandBuffer commands[3];
commands[0] = /* [...] */;
commands[1] = /* [...] */;
commands[2] = /* [...] */;
wgpuQueueSubmit(queue, 3, commands);
// or, safer and avoid repeating the array size:
std::array<WGPUCommandBuffer, 3> commands;
commands[0] = /* [...] */;
commands[1] = /* [...] */;
commands[2] = /* [...] */;
wgpuQueueSubmit(queue, commands.size(), commands.data());
In any case, do not forgot to release the command buffers once they have been submitted:
// Release:
for (auto cmd : commands) {
wgpuCommandBufferRelease(cmd);
}
And if we need to dynamically change the size, we use a std::vector:
std::vector<WGPUCommandBuffer> commands;
// [...] (Allocate and fill in command buffers)
wgpuQueueSubmit(queue, commands.size(), commands.data());
However, we cannot manually create a WGPUCommandBuffer object. This buffer uses a special format that is left to the discretion of your driver/hardware. To build this buffer, we use a command encoder.
Command encoder¶
A command encoder is created following the usual object creation idiom of WebGPU:
WGPUCommandEncoderDescriptor encoderDesc = {};
encoderDesc.nextInChain = nullptr;
encoderDesc.label = "My command encoder";
WGPUCommandEncoder encoder = wgpuDeviceCreateCommandEncoder(device, &encoderDesc);
We can now use the encoder to write instructions. Since we do not have any object to manipulate yet we stick with simple debug placeholder for now:
wgpuCommandEncoderInsertDebugMarker(encoder, "Do one thing");
wgpuCommandEncoderInsertDebugMarker(encoder, "Do another thing");
And then finally generating the command from the encoder also requires an extra descriptor:
WGPUCommandBufferDescriptor cmdBufferDescriptor = {};
cmdBufferDescriptor.nextInChain = nullptr;
cmdBufferDescriptor.label = "Command buffer";
WGPUCommandBuffer command = wgpuCommandEncoderFinish(encoder, &cmdBufferDescriptor);
wgpuCommandEncoderRelease(encoder); // release encoder after it's finished
// Finally submit the command queue
std::cout << "Submitting command..." << std::endl;
wgpuQueueSubmit(queue, 1, &command);
wgpuCommandBufferRelease(command);
std::cout << "Command submitted." << std::endl;
{{Get Queue}}
{{Add queue callback}}
{{Create Command Encoder}}
{{Add commands}}
{{Finish encoding and submit}}
{{Poll device}}
Device polling¶
The above code actually fails when used with Dawn:
Submitting command...
Command submitted.
Queued work finished with status: 4
Note
The present example is so simple that wgpu-native actually completes the submitted work before the device gets released.
As can be seen in webgpu.h, the value 4 corresponds to WGPUQueueWorkDoneStatus_DeviceLost. Indeed, our program terminates right after submitting the commands, without waiting for it to complete, so the device gets destroyed before the submitted work is done!
So, we need to wait a little bit, and importantly we must call tick/poll on the device so that it updates its awaiting tasks. This is a part of the API that is not standard yet, so we must adapt our implementation to the backend:
for (int i = 0 ; i < 5 ; ++i) {
std::cout << "Tick/Poll device..." << std::endl;
#if defined(WEBGPU_BACKEND_DAWN)
wgpuDeviceTick(device);
#elif defined(WEBGPU_BACKEND_WGPU)
wgpuDevicePoll(device, false, nullptr);
#elif defined(WEBGPU_BACKEND_EMSCRIPTEN)
emscripten_sleep(100);
#endif
}
Important
Since wgpu-native holds non-standard functions in wgpu.h to keep them separate from the standard webgpu.h
#ifdef WEBGPU_BACKEND_WGPU
# include <webgpu/wgpu.h>
#endif // WEBGPU_BACKEND_WGPU
Our program now outputs something like this:
Submitting command...
Command submitted.
Tick/Poll device...
Queued work finished with status: 0
Tick/Poll device...
Tick/Poll device...
Tick/Poll device...
Tick/Poll device...
To avoid using an arbitrary number of ticks, we may set a context boolean to true in onQueueWorkDone and break the loop as soon as it is true. But we will shortly call this in the main application loop anyway!
Conclusion¶
We have seen a few important notions in this chapter:
The CPU and GPU live in different timelines.
Commands are streamed from CPU to GPU through a command queue.
Queued command buffers must be encoded using a command encoder.
We must regularly tick/poll the device to updates its awaiting tasks.
This was a bit abstract because even though we can now queue operations, they do not let us see anything yet. In the next chapters we open a graphics window and then use our queue to finally display something!
Note
If you are only interested in compute shaders and do not need to open a window, you may leave the Getting Started section right away and move on to Basic Compute, although some key concepts are still only introduced in the Basic 3D Rendering part, like the Playing with buffers chapter.
Resulting code: step015